In our current evaluation of 28,304 experiments run by Convert prospects, we discovered that solely 20% of experiments attain the 95% statistical significance degree. Econsultancy found the same development in its 2018 optimization report. Two-thirds of its respondents see a “clear and statistically important winner” in solely 30% or much less of their experiments.
So most experiments (70-80%) are both
inconclusive or stopped early.
Of those, those stopped early make a curious case as optimizers take the decision to finish experiments once they deem match. They achieve this once they can both “see” a transparent winner (or loser) or a clearly insignificant take a look at. Normally, in addition they have some knowledge to justify it.
This won’t come throughout as so stunning,
provided that 50% of optimizers don’t have a
normal “stopping level” for his or her experiments. For many, doing so
is a necessity, due to the stress of getting to keep up a sure testing velocity (XXX checks/month)
and the race to dominate their competitors.
Then there’s additionally the potential of a damaging experiment hurting income. Our personal analysis has proven that non-winning experiments, on common, may cause a 26% lower within the conversion fee!
All stated, ending experiments early continues to be dangerous…
… as a result of it leaves the chance that had
the experiment run its meant size, powered by the fitting pattern dimension, its
consequence might have been totally different.
So how do groups that finish experiments early know when it’s time to finish them? For many, the reply lies in devising stopping guidelines that velocity up decision-making, with out compromising on its high quality.
Transferring away from conventional stopping guidelines
For net experiments, a p-value of 0.05 serves
as the usual. This 5 % error tolerance or the 95% statistical
significance degree helps optimizers preserve the integrity of their checks. They
can make sure the outcomes are precise outcomes and never flukes.
In conventional statistical fashions for fixed-horizon testing — the place the take a look at knowledge is evaluated simply as soon as at a set time or at a particular variety of engaged customers — you’ll settle for a consequence as important when you may have a p-value decrease than 0.05. At this level, you possibly can reject the null speculation that your management and remedy are the identical and that the noticed outcomes are usually not by probability.
In contrast to statistical fashions that provide the provision to guage your knowledge because it’s being gathered, such testing fashions forbid you to take a look at your experiment’s knowledge whereas it’s operating. This follow — also referred to as peeking — is discouraged in such fashions as a result of the p-value fluctuates virtually each day. You’ll see that an experiment will likely be important in the future and the subsequent day, its p-value will rise to some extent the place it’s not important anymore.
Simulations of the p-values plotted for 100 (20-day) experiments; solely 5 experiments truly find yourself being important on the 20-day mark whereas many often hit the <0.05 cutoff within the interim.
Peeking at your experiments within the interim can present outcomes that don’t exist. For instance, under you may have an A/A take a look at utilizing a significance degree of 0.1. Because it’s an A/A take a look at, there’s no distinction between the management and the remedy. Nevertheless, after 500 observations in the course of the ongoing experiment, there’s over a 50% probability of concluding that they’re totally different and that the null speculation will be rejected:
Right here’s one other one in every of a 30-day lengthy A/A take a look at the place the p-value dips to the importance zone a number of occasions within the interim solely to lastly be far more than the cutoff:
Appropriately reporting a p-value from a
fixed-horizon experiment means you’ll want to pre-commit to a set pattern dimension or
take a look at length. Some groups additionally add a sure variety of conversions to this
experiment stopping standards and an meant size.
Nevertheless, the issue right here is that having sufficient take a look at site visitors to gas each single experiment for optimum stopping utilizing this normal follow is troublesome for many web sites.
Right here’s the place utilizing sequential testing strategies that assist optionally available stopping guidelines helps.
Transferring towards versatile stopping guidelines that allow quicker choices
Sequential testing strategies allow you to faucet into
your experiments’ knowledge because it seems and use your personal statistical significance
fashions to identify winners sooner, with versatile stopping guidelines.
Optimization groups on the highest ranges of CRO maturity usually devise their very own statistical methodologies to assist such testing. Some A/B testing instruments even have this baked into them and will counsel if a model appears to be profitable. And a few provide you with full management over the way you need your statistical significance to be calculated, along with your customized values and extra. So you possibly can peek and spot a winner even in an ongoing experiment.
Statistician, creator, and teacher of the favored CXL course on A/B testing statistics, Georgi Georgiev is all for such sequential testing strategies that enable flexibility within the quantity and timing of interim analyses:
“Sequential testing permits you to
maximize earnings by early deployment of a profitable variant, in addition to to cease
checks which have little chance of manufacturing a winner as early as doable.
The latter minimizes losses attributable to inferior variants and hastens testing when
the variants are merely unlikely to outperform the management. Statistically rigor
is maintained in all instances.”
Georgiev has even labored on a calculator that helps groups ditch the mounted pattern testing fashions for one that may detect a winner whereas an experiment continues to be operating. His mannequin elements in loads of stats and helps you name checks about 20-80% quicker than normal statistical significance calculations, with out sacrificing high quality.
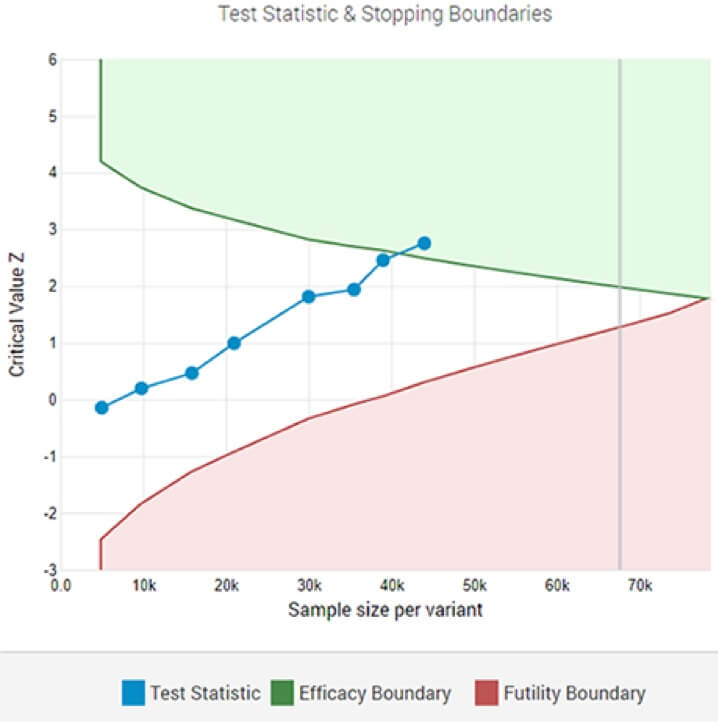

An adaptive A/B take a look at displaying a statistically important winner on the designated significance threshold after the 8-th interim evaluation.
Whereas such testing can speed up your
decision-making course of, there’s one essential facet that wants addressing: the precise influence of the experiment.
Ending an experiment within the interim can lead you to overestimate it.
non-adjusted estimates for the impact dimension will be harmful, cautions Georgiev. To keep away from this, his mannequin makes use of strategies to use changes that consider the bias incurred attributable to interim monitoring. He explains how their agile evaluation adjusts the estimates “relying on the stopping stage and the noticed worth of the statistic (overshoot, if any).” Beneath, you possibly can see the evaluation for the above take a look at: (Observe how the estimated elevate is decrease than the noticed and the interval just isn’t centered round it.)
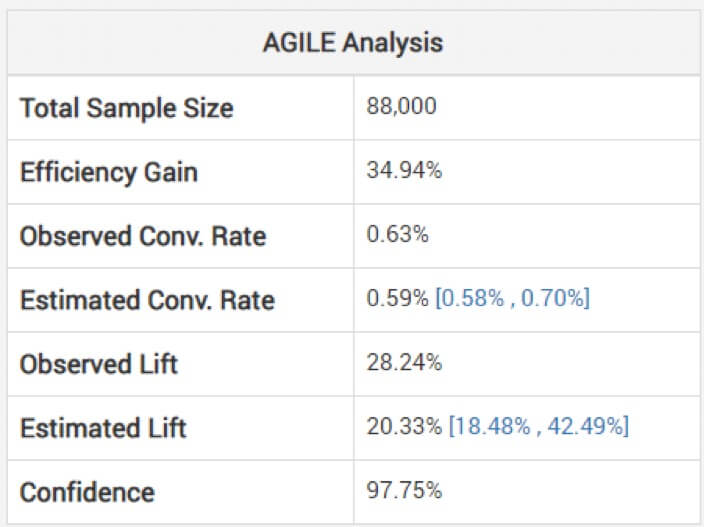

So a win will not be as huge because it appears primarily based in your shorter-than-intended experiment.
The loss, too, must be factored in, since you might need nonetheless ended up erroneously calling a winner too quickly. However this danger exists even in fixed-horizon testing. Exterior validity, nevertheless, could also be an even bigger concern when calling experiments early as in comparison with a longer-running fixed-horizon take a look at. However that is, as Georgiev explains, “a easy consequence of the smaller pattern dimension and thus take a look at length.“
In the long run… It’s not about winners or losers…
… however about higher enterprise choices, as Chris Stucchio says.
Or as Tom Redman (creator of Knowledge Pushed:
Taking advantage of Your Most Essential Enterprise Asset) asserts that in enterprise: “there’s usually extra essential standards than
statistical significance. The essential query is, “Does the consequence rise up available in the market, if just for a quick interval of
time?”’
And it probably will, and never only for a
temporary interval, notes Georgiev, “if it
is statistically important and exterior validity issues have been
addressed in a passable method on the design stage.”
The entire essence of experimentation is to empower groups to make extra knowledgeable choices. So for those who can move on the outcomes — that your experiments’ knowledge factors to — sooner, then why not?
It is perhaps a small UI experiment you can’t virtually get “sufficient” pattern dimension to. It may also be an experiment the place your challenger crushes the unique and you might simply take that guess!
As Jeff Bezos writes in his letter to Amazon’s
shareholders, huge experiments pay huge time:
“Given a ten % probability of a 100 occasions payoff, it’s best to take that guess each time. However you’re nonetheless going to be improper 9 occasions out of ten. Everyone knows that for those who swing for the fences, you’re going to strike out loads, however you’re additionally going to hit some residence runs. The distinction between baseball and enterprise, nevertheless, is that baseball has a truncated final result distribution. While you swing, regardless of how nicely you join with the ball, essentially the most runs you may get is 4. In enterprise, each occasionally, if you step as much as the plate, you possibly can rating 1,000 runs. This long-tailed distribution of returns is why it’s essential to be daring. Huge winners pay for therefore many experiments.“
Calling experiments early, to a terrific diploma, is like peeking each day on the outcomes and stopping at some extent that ensures a great guess.




Initially revealed Could 22, 2020 – Up to date February 08, 2023
Cell studying?
Authors

Editors

Carmen Apostu
In her position as Head of Content material at Convert, Carmen is devoted to delivering top-notch content material that individuals can’t assist however learn by way of. Join with Carmen on LinkedIn for any inquiries or requests.